[WIP] AMADEUS: Advanced Multilingual & Multimudal Assistant Demonstrating Extensive Understanding in Scaled-contexts
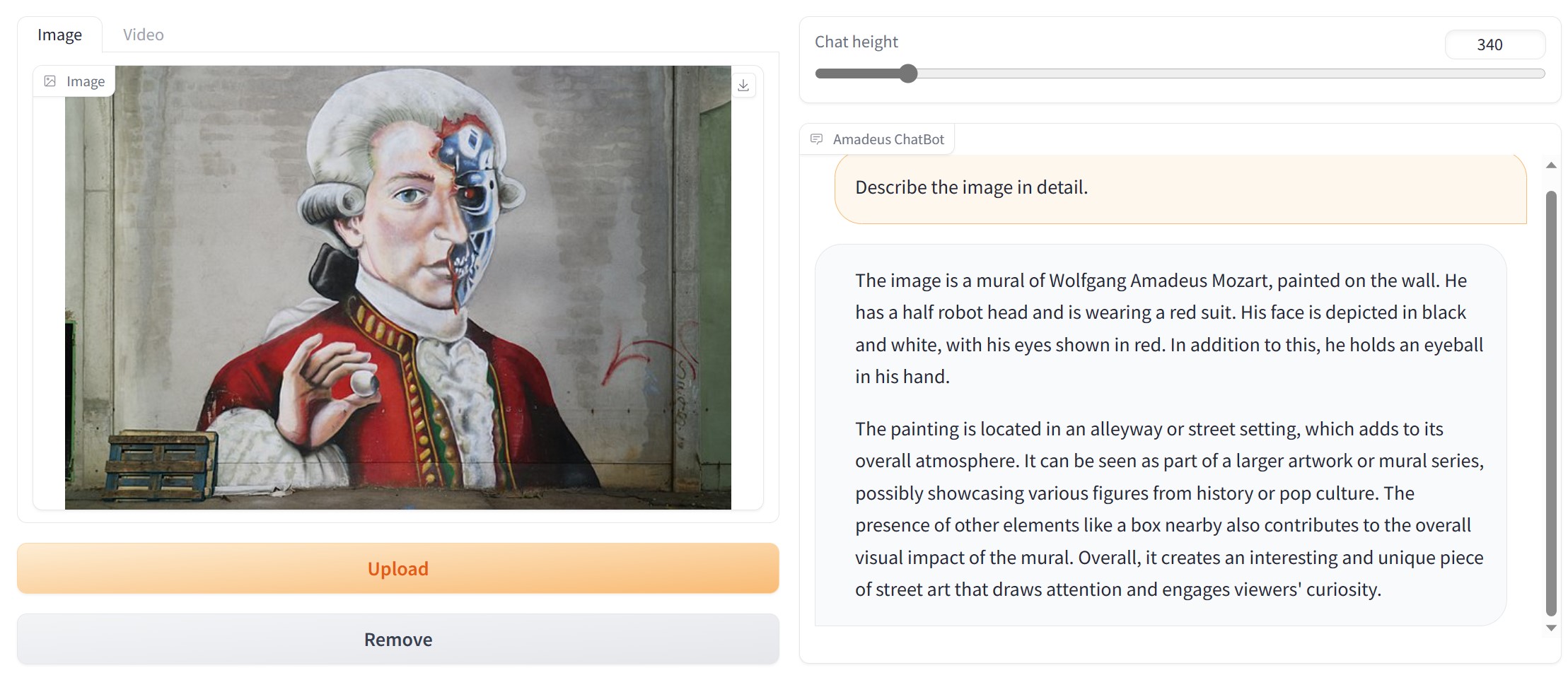
WIP, coming sooooon...
Amadeus is a large language model that offers enhanced linguistic and conversational tasks in English, Chinese (Simplified and Traditional), Japanese, and Deutsch, developed through the insights acquired from the Guanaco Model prototype (Huggingface). This new model introduces several novel features that significantly advance its performance and versatility, including extended context length, a larger tokenizer vocabulary, unsupervised training on a multimodal image-text dataset, template-based instruction tuning, and uncensored model capabilities.
Key Features
1. Extended Context Length
Amadeus stands out for its ability to handle an extended context length of up to
This feature was made possible by the method proposed by Shouyuan Chen et al. (2023) in their paper "Extending Context Window of Large Language Models via Positional Interpolation". The Position Interpolation (PI) technique linearly downscales the position indices to fit within the original context window size, rather than extrapolating beyond the trained context length.
Consider a LLaMA model pretrained with a context window of length
The position encodings used by LLaMA can be represented as:
...where
The attention scores are computed as:
Theoretical analysis shows that the upper bound on the interpolation attention scores:
...is much smaller than extrapolation, making interpolation more stable.
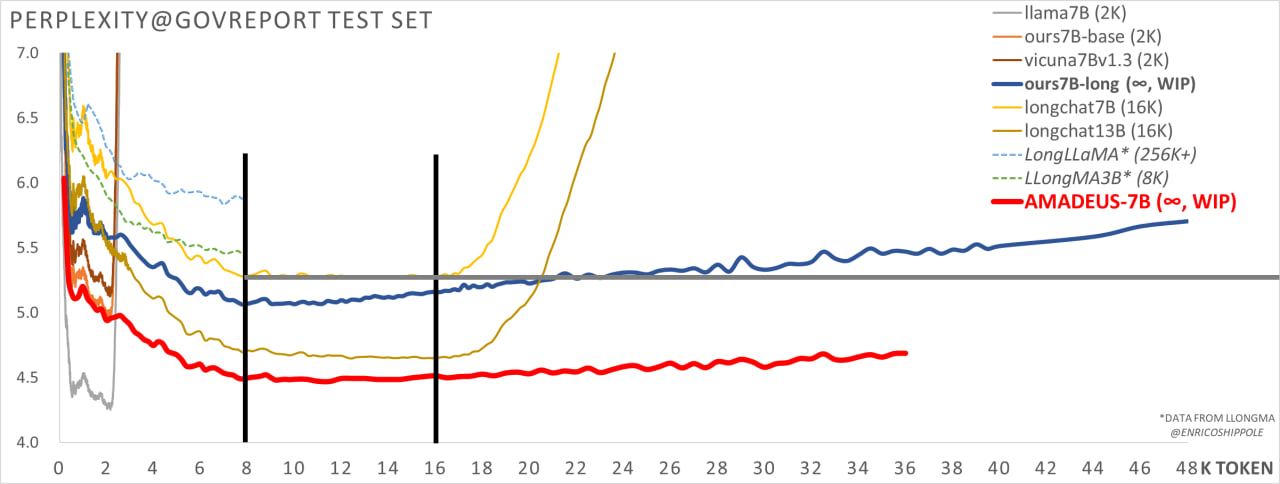
Compared to other large context models, Amadeus' 7B model surpassed the SOTA open-source model, Longchat 16K 13B model in perplexity, demonstrating the model's superior performance.
2. Expanded Tokenizer Vocabulary
The tokenizer's vocabulary in Amadeus has been expanded to
3. Unsupervised Training on Multimodal Image-Text Dataset
Amadeus has undergone unsupervised training on a multimodal image-text dataset, adopting the BLIP2 Q-Former trained on a larger foundational LLM Vicuna 13B. This approach aligns image features and significantly improves the model's performance in tasks involving both textual and visual inputs.
The BLIP2 Q-Former is derived from the InstructBLIP-13B, as detailed in "InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning" .
4. Template-Based Instruction Tuning
Amadeus is designed to adapt to various instruction tuning templates in a 0-shot or 1-shot setting. The model underwent supervised training on a wide array of common instruction tuning templates. This feature allows for better context attention, especially when using the model's template rules.
5. Uncensored Model
AMADEUS is an uncensored model that has been trained on a vast amount of text, including potentially harmful, explicit, and illegal content. The model does not have a built-in ethical constraint, hence it requires careful handling. While this feature provides a wider range of responses, it is crucial to use the model responsibly and be aware of the potential risks.
6. White Label Model
Unlike many AI models, Amadeus is a white label model that does not identify itself as an AI Assistant. It possesses a degree of human-like emotion and can simulate characters as needed. The model can assume specific roles, personalities, and identities based on the System Prompt, allowing for role-playing conversations or functioning as an emotionless AI Assistant. It also has the ability to censor or uncensor its outputs using the System Prompt.
7. Full Functionality within 6GB CUDA Memory
The quantized model can run complete content, including Visual Question Answering (VQA), within 6GB CUDA memory or CPU memory (though slower). This feature makes the model more accessible and scalable across various hardware configurations.
8. Support for Video Question Answering
Amadeus extends its VQA capabilities to videos, enabling users to ask questions about a video's content. This advancement further enhances the model's multimodal capabilities, providing a richer and more interactive user experience.
Training and Carbon Footprint
Amadeus was trained for approximately 28 days of GPU time on NVIDIA A100 Tensor Core GPUs, which would cost around
The training data utilized OpenAI GPT and Claude API for supervised instruction tuning, and cleansing of long text and other unsupervised datasets. The total cost of these datasets, based on the official prices of OpenAI and Claude, is approximately
Conclusion
Amadeus represents a significant advancement in the field of instruction-following language models, offering extended contextual understanding, expanded vocabulary, multimodal capabilities, and a range of other innovative features. However, it is important to note that while Amadeus strives to provide accurate and helpful responses, it is crucial to cross-verify information from reliable sources for knowledge-based queries and to exercise caution due to its uncensored nature. As research in this field continues to evolve, models like Amadeus will continue to push the boundaries of what is possible, offering increasingly advanced and versatile tools for a wide array of applications.