[在制品] AMADEUS:在扩展上下文中展现广泛理解能力的高级多语言与多模态助手
WIP,即将推出...
Amadeus 是一款大型语言模型,能够在英语、中文(简体和繁体)、日语和德语中提供增强的语言和会话任务。它通过从 Guanaco Model 原型(Huggingface)中获得的见解进行开发。这款新型号引入了几个新颖的功能,显著提高了其性能和通用性,包括扩展上下文长度、更大的 tokenizer 词汇表、无监督训练的多模态图像文本数据集、基于模板的指令调谐和无审查模型功能。
主要特点
1. 扩展上下文长度
Amadeus 的突出特点是能够处理最多
这个功能得益于 Shouyuan Chen 等人(2023)在他们的论文 "Extending Context Window of Large Language Models via Positional Interpolation" 中提出的方法。位置插值(PI)技术通过线性缩小位置指数来适应原始上下文窗口大小,而不是超出训练的上下文长度进行推理。
考虑预训练的 LLaMA 模型,上下文窗口长度为
LLaMA 使用的位置编码可以表示为:
其中,
注意力分数计算为:
理论分析表明,插值注意力分数的上界:
比外推小得多,使得插值更稳定。
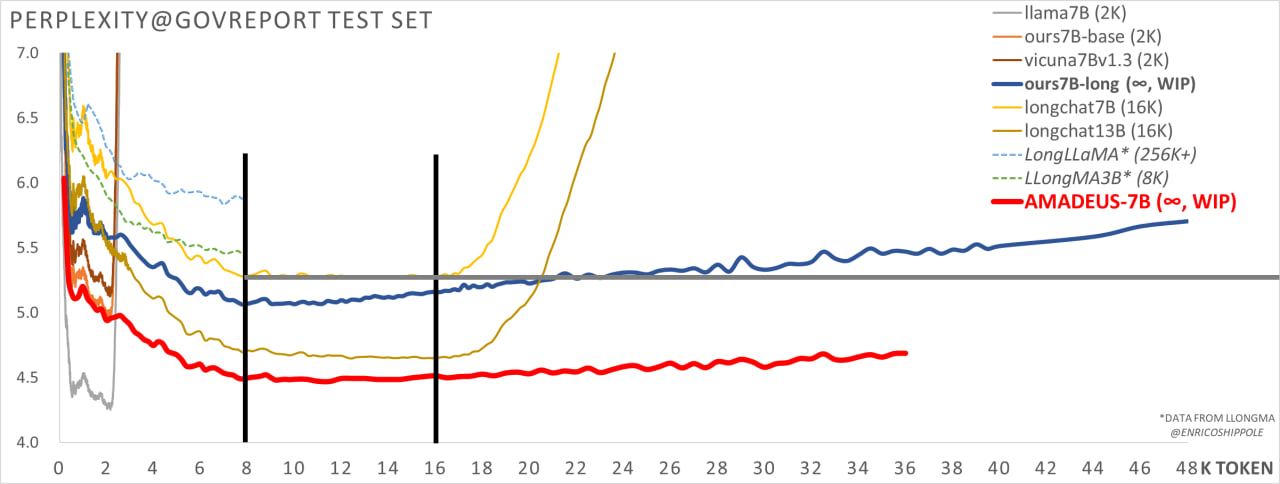
与其他大型上下文模型相比,Amadeus 的 7B 模型在困惑度上超过了 SOTA 开源模型 Longchat 16K 13B 模型,显示出模型的卓越性能。
2. 扩展的分词器词汇表
Amadeus中的分词器词汇表已扩展到
3. 在多模态图像-文本数据集上进行无监督训练
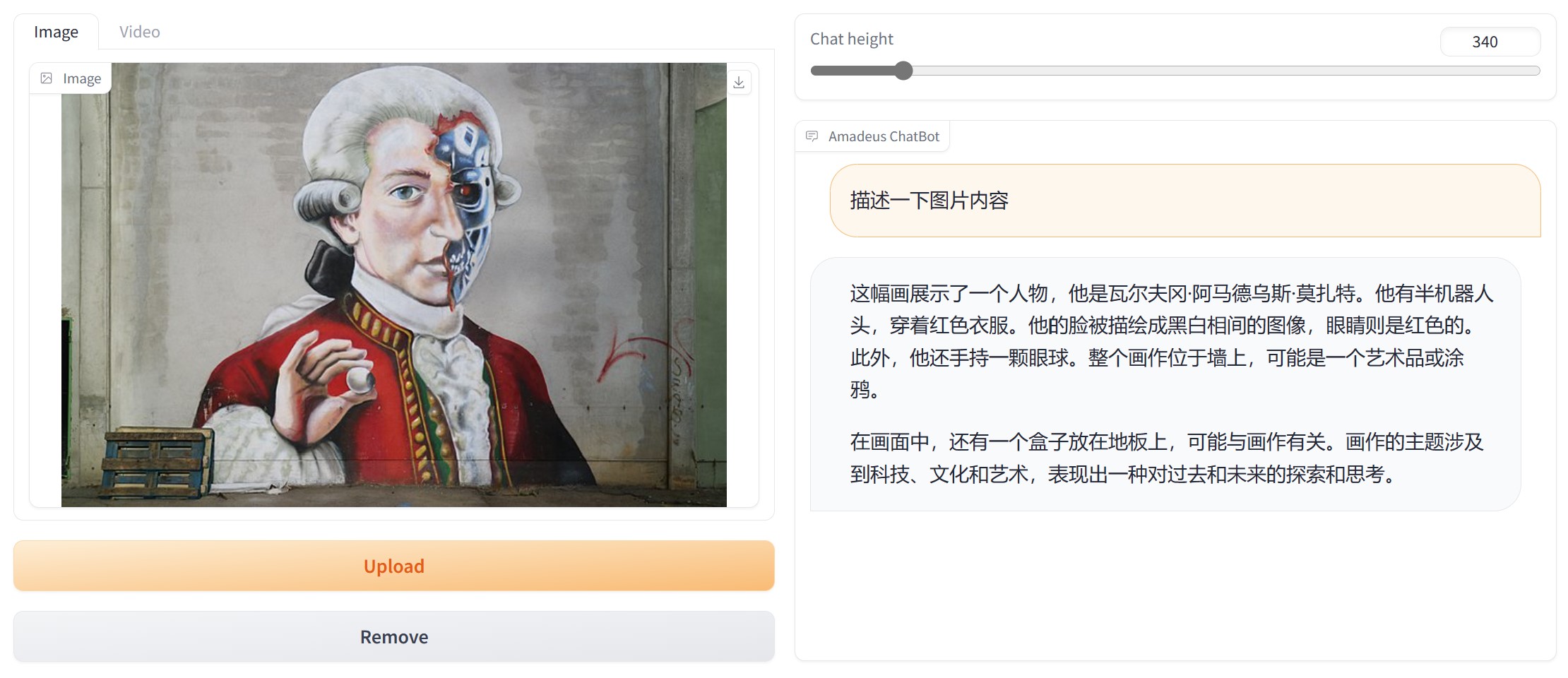
Amadeus在一个多模态图像-文本数据集上进行了无监督训练,采用了在更大的基础语言模型Vicuna 13B上训练的BLIP2 Q-Former。这种方法对齐了图像特征,并显著提高了该模型在涉及文本和视觉输入的任务中的表现。
BLIP2 Q-Former源自InstructBLIP-13B,详见"InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning" 。
4. 基于模板的指令调整
Amadeus 被设计成能适应各种在0-shot或1-shot设置中的指令调整模板。该模型在一系列常见的指令调整模板上进行了监督训练。这个特性使得在使用模型的模板规则时,更好地关注上下文。
5. 未经审查的模型
Amadeus 是一个未经审查的模型,它在大量的文本上进行了训练,包括可能的有害、明确和非法内容。该模型没有内置的道德约束,因此需要谨慎处理。虽然这个特性提供了更广泛的响应范围,但使用模型时需要负责任,并注意可能的风险。
6. 白标模型
与许多 AI 模型不同,Amadeus 是一个不把自己标识为 AI 助手的白标模型。它具有一定程度的类人情感,并可以根据需要模拟角色。该模型可以根据系统提示扮演特定的角色、人格和身份,进行角色扮演对话或作为一个没有情感的 AI 助手。它还能通过系统提示对输出进行内容审查或取消审查。
7. 6GB CUDA 内存内完整功能
量化模型可以在 6GB CUDA 内存或 CPU 内存(尽管速度较慢)内运行完整内容,包括视觉问题回答(VQA)。这一特性使得模型在各种硬件配置上更具可访问性和可扩展性。
8. 支持视频问题回答
Amadeus 将其 VQA 能力扩展到视频,使用户可以询问有关视频内容的问题。这一进步进一步增强了模型的多模态功能,为用户提供了更丰富、更互动的体验。
训练和碳足迹
Amadeus 在 NVIDIA A100 Tensor Core GPU 上进行了大约 28 天的 GPU 时间训练,如果在 Google Cloud Platform(GCP)上租用,成本约为 2466.24 美元。根据功耗、时间和当地电网产生的碳排放计算,训练过程中排放的碳量为 64.51 公斤 CO2 当量。
训练数据利用了 OpenAI GPT 和 Claude API 进行监督指令调整,以及清洗长文本和其他无监督数据集。基于 OpenAI 和 Claude 的官方价格,这些数据集的总成本约为 15,000 美元,其中一半已通过 GuanacoDataset 开源给社区。
结论
Amadeus 在遵循指令的语言模型领域取得了重大进展,提供了更广泛的上下文理解、扩展词汇、多模态功能以及其他创新特性。然而,需要注意的是,虽然 Amadeus 力求提供准确和有用的回应,但在知识查询方面,务必从可靠来源进行交叉验证,以防止因其未经审查的性质带来的风险。随着这个领域的研究不断发展,Amadeus 等模型将继续拓展可能的边界,为各种应用提供越来越先进和多功能的工具。